Recently I’ve started experimenting with vschaos2, a “vintage-flavoured neural audio synthesis package” that can be trained on spectral information of audio data in a supervised or semi-supervised environment. The package has been created by Axel Chemla–Romeu-Santos at IRCAM.
As does RAVE, vschaos2 works with the variational auto encoder architecture, a network that compresses input information to a compact representation in latent space via an encoder and translates these representations again through a decoder to the same data quality as the input, e.g. audio data.
vschaos2 models are delivered as torchscript (.ts) files that can be used in real time environments (Pure Date, Max) using the nn~ object. They are quite lightweight and perform smoothly also on machines that are not high end configuration.
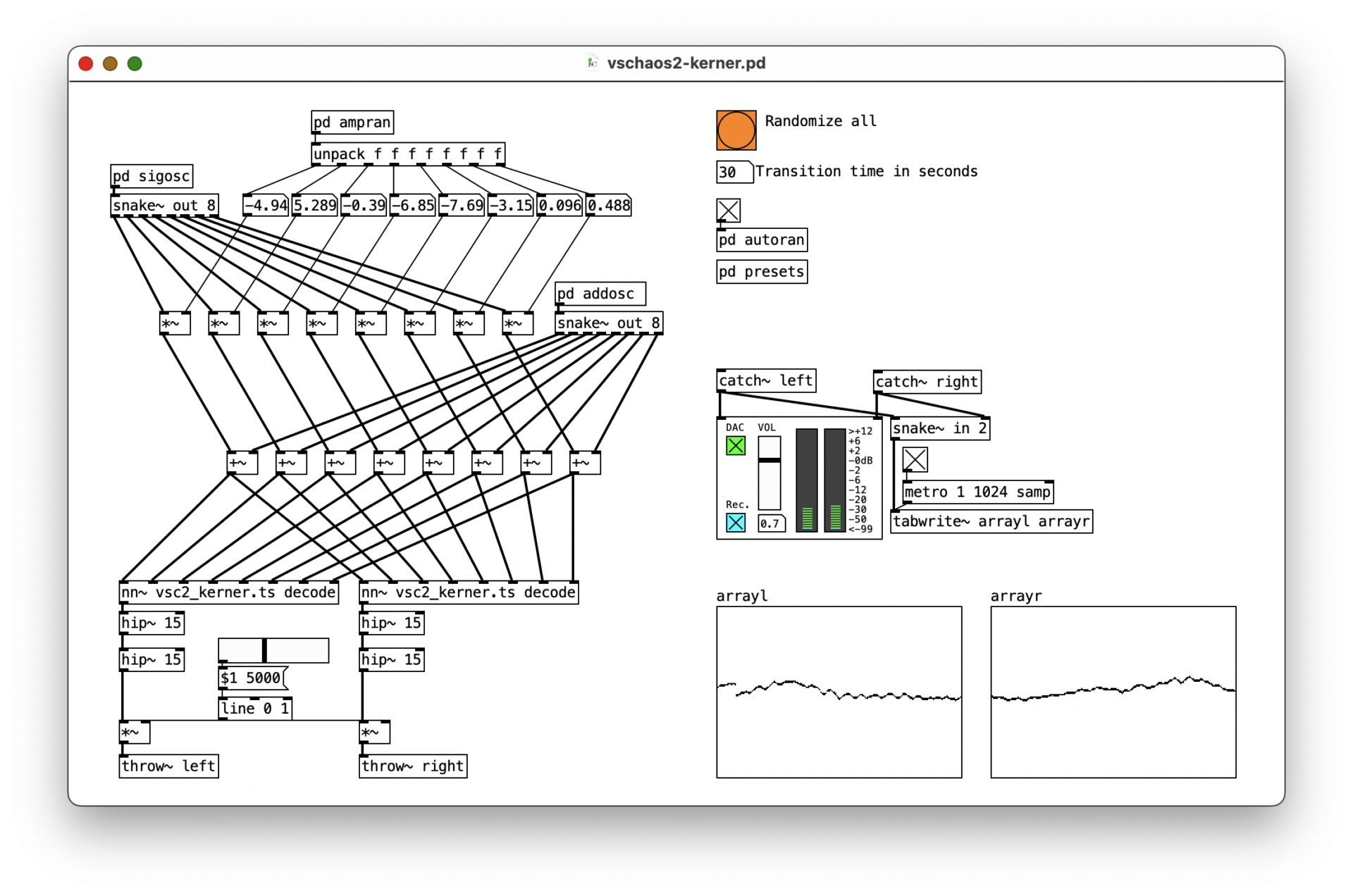
For a quick showcase, I’ve trained a vschaos2 model on my album “Kerner” and wrote a patch in Pure Data that simulates latent encodings by generating signal value streams that the decoder converts into audio signal.
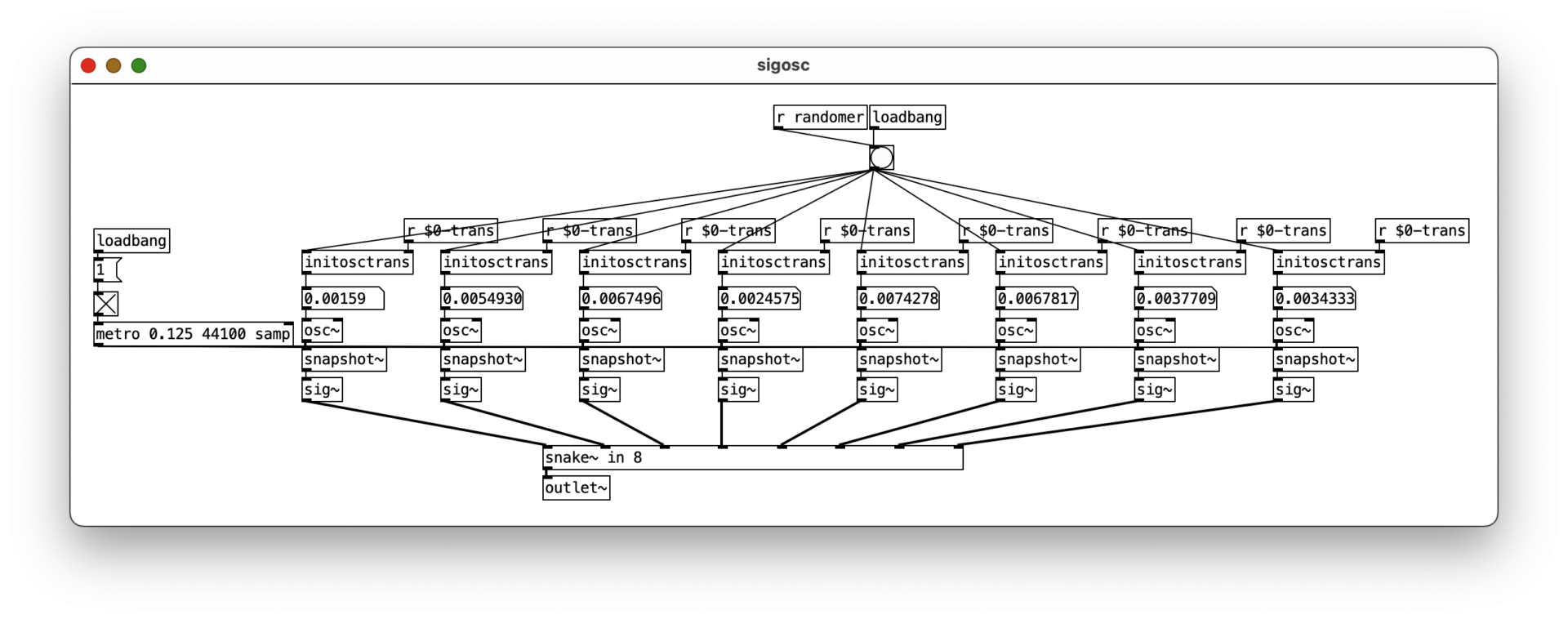
By randomly changing these values while running, the model outputs a constantly different stream of drones derived from the spectral information it learned from the tracks of “Kerner”.