
The practice of “bending” systems, that is: modifying or disrupting their intended functions, has been a recurring aspect of artistic practice across different cultural contexts. More recently, the bending of neural networks has become a point of interest for researchers and practitioners, driven partly by the desire to expand the models’ generative capabilities through alterations to their underlying structures for processing and reproducing information.
“One common criticism of using deep generative models in an artistic and creative context, is that they can only reproduce samples that fit the distribution of samples in the training set. However, by introducing deterministic controlled filters into the computation graph during inference, these models can be used to produce a large array of novel results.”
Broad et. al. “Network Bending: Expressive Manipulation of Generative Models in Multiple Domains” https://www.mdpi.com/1421002
A few months back I came across Błażej Kotowski’s fork of nn~. It adds a new functionality to the nn~ object that exposes neural net layers along with their weights and biases for compatible model architectures (e.g. RAVE, vschaos2, MSPrior or AFTER). It also allows you to modify weights and biases and push them back into the respective layer. That means we can hack into these models and do some network bending experimentation in real time now, purposefully altering, partly disrupting the capabilities of the model both in terms of processing and creating audio information.
“Bender” component for Pure Data
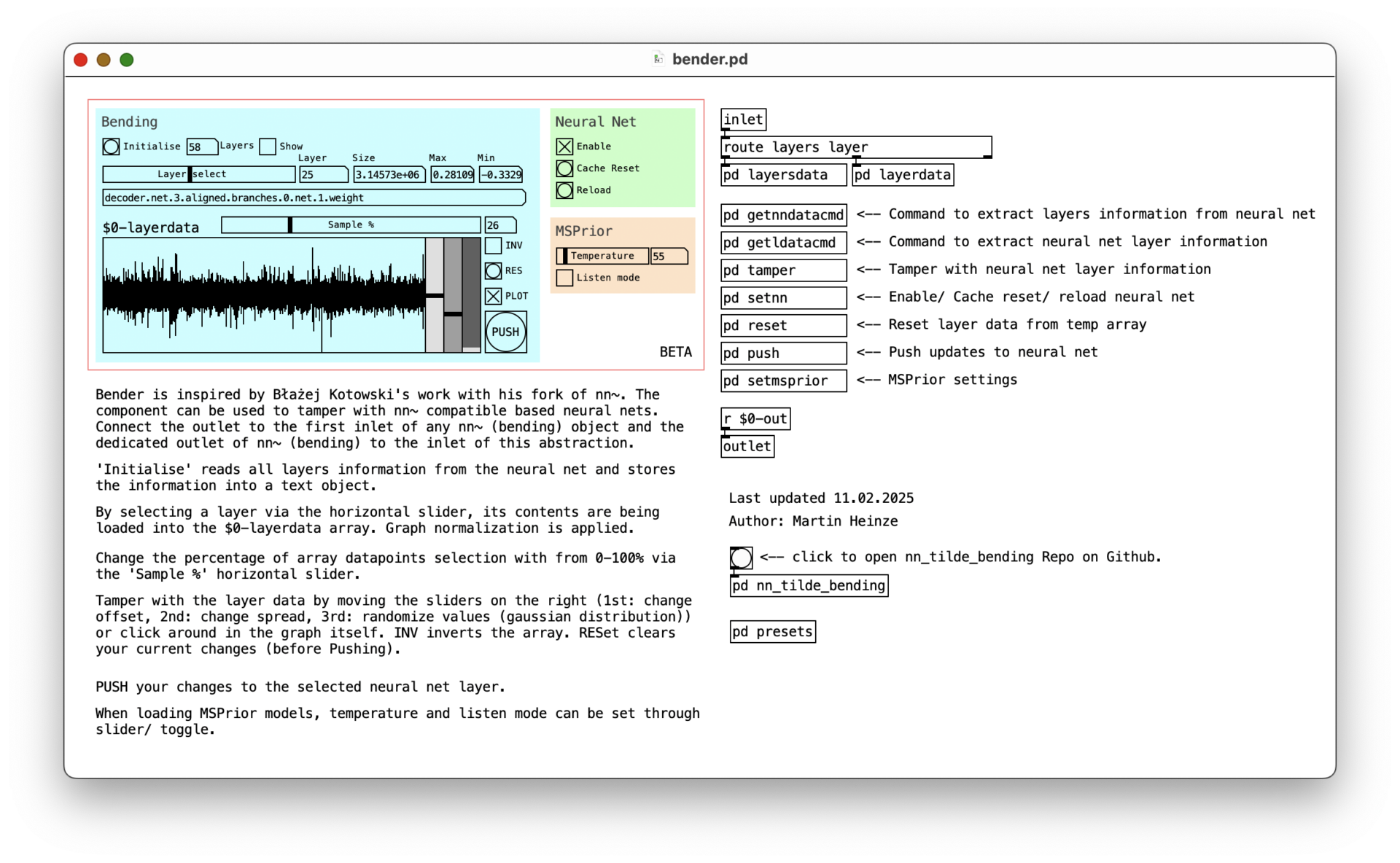
Inspired by Błażej’s video, i’ve created a component in Pure Data that can modify the neural net’s data in various ways, such as off-setting, randomizing or inverting values. That component is called “Bender” and is available on Github.
Since the changes can have a dramatic effect on the sound, I’ve added a method that lets you control the percentage of data points affected when applying adjustments. This makes the results much less extreme, allowing you to bend your neural network in a more subtle way.
As shown in the video above, you can select the desired percentage by moving the slider to a position between 0 and 100%. The number of data points is then calculated and evenly distributed within the selected layer. Any adjustments made using the sliders next to the array will only affect these specific data points, not the entire array.
Limitations
The number of data points per layer can range from a few thousand to millions, depending on the model’s architecture and training setup. This can impact the real-time performance of network bending, especially based on your workstation’s configuration. I haven’t found a practical solution for this issue yet, but it might be addressed in the future.



